偏差方差问题
偏差:表示针对现有数据进行拟合拟合如果模型简单拟合的效果会不好
出现高偏差的现象
方差:模型对数据已经拟合的相当好了,在泛化上出现了高方差的现象
高偏差代表欠拟合高方差带边过拟合
人们往往看到的只是现有数据,所以对现有数据进行的操作时减小偏差
妄图通过有限数据来创造无限数据情况下的模型
会产生一个矛盾曲线
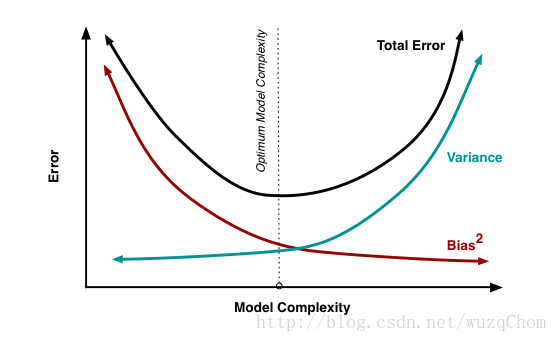
两条曲线会随着模型的复杂度变化而出现相反的变化趋势
bagging 和boosting
bagging可以减小方差
对样本进行又放回采样 k次
用k个子数据来训练k个模型 模型可以是任何弱模型(决策树,svm,感知器,等)
一个样本通过所有模型 得到的结果求均值或者投票 得到最终结果
boosting可以减小偏差
使用所有样本输入到模型中,将错分样本当做误差函数,错分样本,反馈给样本的权重,错分的样本权重变大 正确的权重变小
直到满足错误了或者没有错误的,在全样本上会造成过拟合的现象。
LR(逻辑回归)
将LR看成两点分布,再求极大似然,
两点分布的函数P(X=x)=p^x*(1-p)^(1-x)
设置似然函数,求导的出来的公式就是交叉熵损失函数
- 线性回归是误差为高斯分布的极大似然估计
overfitting
dropout regularization batch normalization
batch normalization 归一化可以让各个特征的范围是一致的 不会出现某个特征是100-100000而某个是0-1,导致特征不在一个范围为 这样的梯度会很难受 模型训练起来权值变化不一致。一个是圆形的一个是团员的
regularization L1 L2
L1具有稀疏性 先验分布服从拉普拉斯分布
L2服从高斯分布
判别与生成
由数据唯一决定的是判别 svm 决策树 神经网络
由数据学习联合概率密度的是生成模型 HMM 贝叶斯 高斯混合
hash算法
数据结构(树 队列 栈)
FEATURED TAGS
c语言
c++
面向对象
指针
容器
python
函数
数据结构
回归
损失函数
神经网络
机器学习
似然函数
极大似然
标准化
深度学习
卷积网络
参数估计
beta分布
数据处理
gradio
模型工程化
网页
模型加速工具
c++实现
变量
占位符
tensorflow
线性回归
学习tensorflow
HMM
RNN
强化学习
LSTM
pandas
不定长序列损失
pytorch
目标检测
RPN
非极大值抑制
ROIpooling
VGG16
Transformer
BERT
Python
装饰器
方法
Pytorch
FPN
图像分类
CNN
多模态
生成
GPT
Tranformer
生成模型
audio