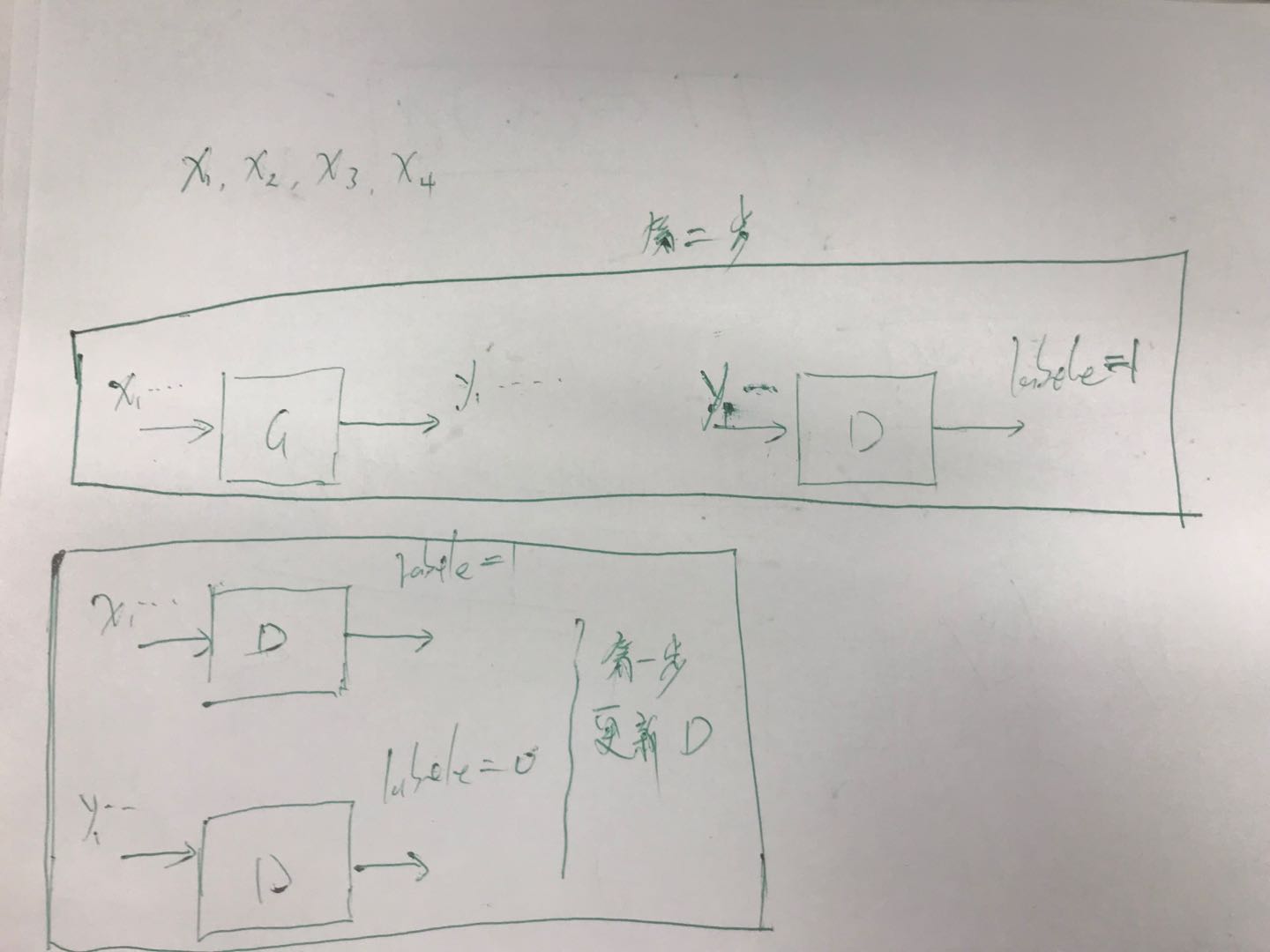
GAN的常识性原理
对于一个生成模型,大部分情况下就是样本的分布模型。通常情况下一个生成模型相当于一个分布转化器,我们有训练
样本的采样数据,通过生成模型将这个数据可以转化为领一个分布的采样数据,这就是生成器。单独训练生成器,需要
人为指定标签,但是GAN就不用了,它让机器自己指定。
GAN分为两个阶段,首先第一个是判别阶段我们需要判别器能判别出,哪些数据是实际数据哪些数据是生成器生成
的数据。判别器就是个二分类器,标签已经默认了,再第一阶段,实际输入到判别器中的数据有:1实际数据,该部分
数据的标签是1,2生成器输出的数据,该部分数据的标签是0,使用这两部分数据更新判别器。
第二阶段是更新生成器,生成器如何更新呢,从生成器的角度看的话,我们要让生成器的输出尽量欺骗判别器,也就是
在生成器部分我们需要让生成器的输出是真的所以这部分的输出输入到判别器中判断后的标签是1,然后得到损失更新
生成器。
样本数据是x 生成器生成数据是y,在这个过程中我们可以为生成器增加一个它自身的损失,一般情况下就是拟合损失。
实现一个简单的GAN
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=10, help="dimensionality of the latent code")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
def reparameterization(mu, logvar):
std = torch.exp(logvar / 2)
sampled_z = Variable(Tensor(np.random.normal(0, 1, (mu.size(0), opt.latent_dim))))
z = sampled_z * std + mu
return z
##编码部分,属于生成器的一部分
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
)
self.mu = nn.Linear(512, opt.latent_dim)
self.logvar = nn.Linear(512, opt.latent_dim)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
x = self.model(img_flat)
mu = self.mu(x)
logvar = self.logvar(x)
z = reparameterization(mu, logvar)
return z
##解吗的结果就是生成器的输出
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh(),
)
def forward(self, z):
img_flat = self.model(z)
img = img_flat.view(img_flat.shape[0], *img_shape)
return img
#判别结果必须是二分类,是否是生成器生成
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(opt.latent_dim, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, z):
validity = self.model(z)
return validity
# Use binary cross-entropy loss
adversarial_loss = torch.nn.BCELoss()
pixelwise_loss = torch.nn.L1Loss()
# Initialize generator and discriminator
encoder = Encoder()
decoder = Decoder()
discriminator = Discriminator()
if cuda:
encoder.cuda()
decoder.cuda()
discriminator.cuda()
adversarial_loss.cuda()
pixelwise_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(encoder.parameters(), decoder.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits"""
# Sample noise
z = Variable(Tensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
gen_imgs = decoder(z)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.shape[0], 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.shape[0], 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
encoded_imgs = encoder(real_imgs)
decoded_imgs = decoder(encoded_imgs)
# Loss measures generator's ability to fool the discriminator
#pixelwise_loss 这个就是生成器的自身损失,有的话可以加上,保证生成的图片更好。
#这一部分是生成器的损失计算,首先是要让判别器认为生成器生成的是真的,其次还有生成器自身的损失
g_loss = 0.001 * adversarial_loss(discriminator(encoded_imgs), valid) + 0.999 * pixelwise_loss(
decoded_imgs, real_imgs
)
# 更新生成器的参数
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as discriminator ground truth
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
#然后计算判别器的损失,这部分的损失计算时站在判别器的角度,我要判别出所有的假的东西。
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(z), valid)
fake_loss = adversarial_loss(discriminator(encoded_imgs.detach()), fake)
d_loss = 0.5 * (real_loss + fake_loss)
#更新判别器
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
最好的训练结果是,判别器判断不出生成器生成的东西是真是假。也就是判别器的输出概率是0.5