看到不懂我吃屎
先整体介绍一下,他是干嘛的,和前提条件,输入时啥输出是啥,然后分别详细介绍,每个功能块的作用,最后介绍如何将这些功能块连接起来,需要看
代码,代码是最好理解原理的方法
整体功能
FasterRCNN主要是是用来做目标检测,具体说就是一张图片上有多个物体,FasterRCNN可以将物体以矩形框的形式框出来同时识别出框出来的物体是啥。
但是前提是,首先是固定的物体类别,不能有未知的物体。输出结果是框的坐标和每个框的类别。如图所示,同时输入单张图片,不能同时处理多个输入
不模型是端到端的训练
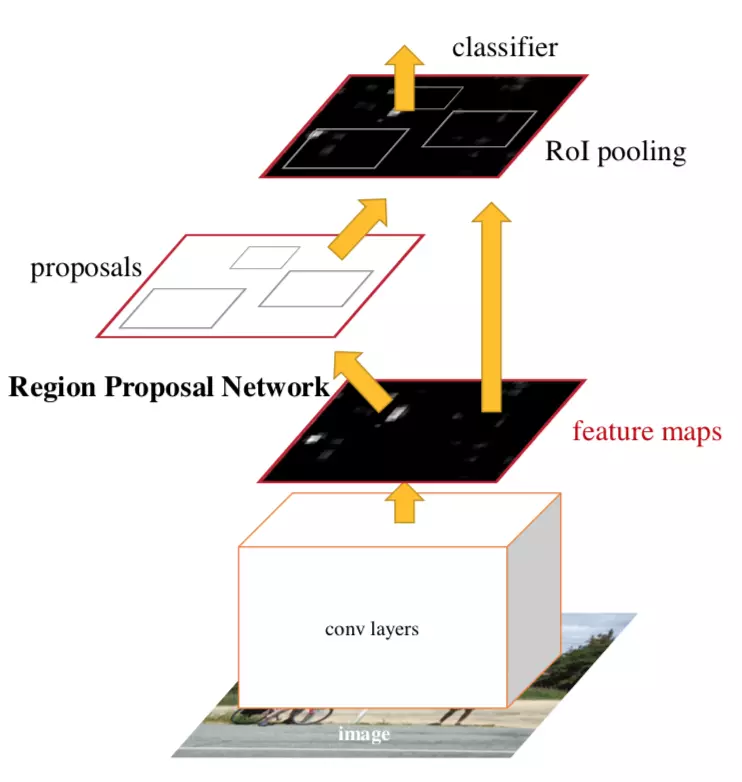
特征提取VGG
第一个是特征提取,首先提取一张图片的特征,使用vgg卷积网络,去掉全连接,输入是一张图片输出是一个多通道的featuremap,注意是一个具体形状如
1*512*32*32,1个样本512通道大小是32*32的特征数据。,也可以构建成FPN的网络,输出多个,重复操作
大概使用pytorch构建的模型就长这B样,每个MaxPooling都会使输出的图片相对原始图片缩减2倍,
最后会在这个特征图上用RPN输出的框来框区域,然后对这些区域惊醒ROIpooling
class VGG16(nn.Module):
def __init__(self, bn=False):
super(VGG16, self).__init__()
self.conv1 = nn.Sequential(Conv2d(3, 64, 3, same_padding=True, bn=bn),
Conv2d(64, 64, 3, same_padding=True, bn=bn),
nn.MaxPool2d(2)) #减小两倍
self.conv2 = nn.Sequential(Conv2d(64, 128, 3, same_padding=True, bn=bn),
Conv2d(128, 128, 3, same_padding=True, bn=bn),
nn.MaxPool2d(2))
network.set_trainable(self.conv1, requires_grad=False)
network.set_trainable(self.conv2, requires_grad=False)
self.conv3 = nn.Sequential(Conv2d(128, 256, 3, same_padding=True, bn=bn),
Conv2d(256, 256, 3, same_padding=True, bn=bn),
Conv2d(256, 256, 3, same_padding=True, bn=bn),
nn.MaxPool2d(2))
self.conv4 = nn.Sequential(Conv2d(256, 512, 3, same_padding=True, bn=bn),
Conv2d(512, 512, 3, same_padding=True, bn=bn),
Conv2d(512, 512, 3, same_padding=True, bn=bn),
nn.MaxPool2d(2))
self.conv5 = nn.Sequential(Conv2d(512, 512, 3, same_padding=True, bn=bn),
Conv2d(512, 512, 3, same_padding=True, bn=bn),
Conv2d(512, 512, 3, same_padding=True, bn=bn))
def forward(self, im_data):
# im_data, im_scales = get_blobs(image)
# im_info = np.array(
# [[im_data.shape[1], im_data.shape[2], im_scales[0]]],
# dtype=np.float32)
# data = Variable(torch.from_numpy(im_data)).cuda()
# x = data.permute(0, 3, 1, 2)
x = self.conv1(im_data)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
return x
最后的结果是一张3通道的图片变成512通道的图片,这部分提取的特征需要进行保留,以后用。
RPN 网络
这部分主要是筛选出框,和每个框是前景的概率,在RPN中有两个网络,第一是输出一个锚点上所有框的前后景类别,另一个网络是输出一个锚点上
所有框的位置偏移,使用这个偏移对锚点框进行偏移。
筛选锚点框确定锚点
VGG的输出就是锚点,featuremap上每个点都是锚点,然后以锚点为中心画框,有三种不同的面积和三种不同长宽比,一个锚点会有9个框
已知一张原始图片经过VGG后会缩小原来的N倍,所以将所有框的大小扩展N倍,得到锚点在原始图片上所有的框的坐标。
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], #生成锚点在原图上的框
scales=2**np.arange(3, 6)):
base_anchor = np.array([1, 1, base_size, base_size]) - 1
ratio_anchors = _ratio_enum(base_anchor, ratios) #一个面积下的框
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
return anchors
def _whctrs(anchor): #将框左边变为框长度和中心点坐标
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr): #将框中心左边变为框坐标
ws = ws[:, np.newaxis] #变成列表示
hs = hs[:, np.newaxis]
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors
def _ratio_enum(anchor, ratios): #返回锚点的中心坐标和边框宽高 相同面积的3种边框 面积相同宽高比不同
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h
size_ratios = size / ratios
ws = np.round(np.sqrt(size_ratios))
hs = np.round(ws * ratios)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _scale_enum(anchor, scales): #相对原图缩放
w, h, x_ctr, y_ctr = _whctrs(anchor) #计算中心点坐标和宽高
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors #返回不同尺寸的在原图上同一宽高比的框
通过锚点框得到预测框
锚点框有了,我们需要构建一个回归网络,该网络回归得到每9个锚点框偏移量,以一批9个框,过回归网络,记录回归结果,该结果是RPN
初步的输出结果。未经训练的回归网络的输出结果。同时记录一框是前后景的概率这个概率用来筛选框。
筛选预测框
同时输出的框太多了需要过滤掉一下框,主要策略有,超出图片以外的去掉,去掉预测框面积小于某个值的,去掉相似框(NMS)
前面的好理解,因为图片上的物体不可能超出图片自身,设定阈值面积,就是为了防止过拟合,或者太多的框,太小的框。
现在说说NMS 也就是非极大值抑制,简单说就是去掉相似的框。如果两个框重叠的面积很大,那这两个框只选择其中一个就可以。
选择方法是看前后景的概率,选择大的。
ROIpooling
RPN的输出是坐标,在原始图象上物体的框坐标,将这个框缩放到特征图上可以得到特征图上一些框出来的范围,对这些范围进行
自适应pooling,一个RNP框会得到一个1*512*7*7的特征图,1表示一个prn框,512表示fittermap的个数,7*7表示一个在
原图的RPN框缩放到特征图大小后,等分成49份做pooling,有多少RPN框就会得到多少个1*512*7*7个特征图,
输出前一层
输出一共有两类,第一类是类别,第二类是框坐标,以voc数据为例,有21类物体所以第一个是21分类器。,同时要输出边框坐标.
输出是21*4的边框偏移量。以一定方式从中选择实际的偏移量。
损失计算
训练数据的构建是通过锚点框和gt框的IOU计算得到,先说第一步回归的损失,先找到每个锚点框对应的最好的gt框,这个最好就是
IOU最大,找到后计算变化量,这个量会作为回归的标签值,同时要记录最合适的类别维第二部分类准备。此时是所有的框都参与回归
计算,虽然有些框不符合要求。但是依然参与回归训练。然后是第一步的分类数据,还是计算每个语实际框的IOU,超出边界的去掉,
然后找到每个框最匹配的gt框的iou,做一个阈值,如果大于0.7认为是正样本,如果小于0.3认为是负样本。这样就可以对前后景进行
训练了。
总的来说所有的训练数据都需要通过计算锚点框和gt框的IOU得到
总体的过程
经过RIOpooling后 得到N*512*7*7个输出拉升,输出到全连接,Linear(512*7*7,80),Linear(512*7*7,4)