数据
依然是目标检测,画框和识别框中的物体,同时以coco数据为例,首先确定有80个类别,也就是说一张图片最多包含80个类别的物体
数据就是图像数据,标签是每个框中物体的中心点坐标和宽高和类别。
网络结构
前面都是卷积网络,就是特征提取,后面会对特征图进行连接和残差操作,就是有些特征直接连接,有些特征需要进行叠加,然后需
要3中不同的尺度,每种尺度都会对应不同效果。
首先选择特征提取网络Darknet53网络,就是有53层卷积的网络。同时使用2步卷积代替pooling可以让网络训练更快。
先画一下网络结果。从图上看,13*13的特征经过上采样会连接16倍下采样的特征
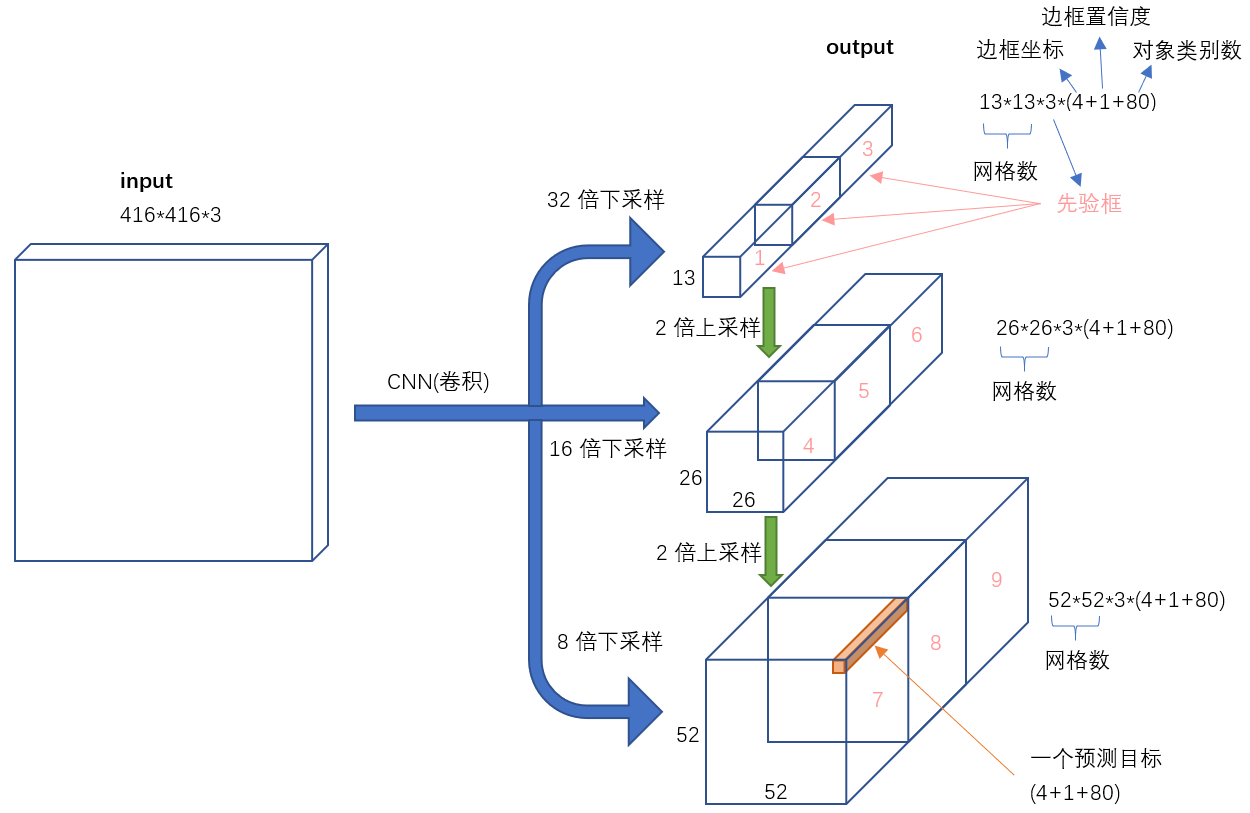
首先是初始阶段,一张图片经过conv网络提取特征,同时确定缩放倍数,缩放倍数对应不同的尺度,
表面上看相当于将图像分成多少个小块,分的越细越能处理细节,在这些细节中我们需要明确由三
种不同的输出。每个输出后面会处理求损失。以一个输出为例,13的输出。有13*13*3*(80+1+4)
个输出,有13*13*3个框,每个框是80类中的一类,这个框的坐标有四个值,同时给出一个置信度
一张图片有好多框,(三种加起来超过1万多个框了)。其中的3表示每个候选框会有三种预选框
预测结果
所有框的结果其实都是在先验框的基础上回归得到的,简单来说就是现在图上给出一个框,每个尺度下给出三种鲜艳框,大概意思就是
每个点下有三种可能预测框。然后我们对这三个框改变大小和位置,得到结果。通过查看代码查看最后输出的结构看
r'''
输出时的结果,这里的x表示输入,来自上面结果输出,每个尺寸下都会产生一个x一共有三种。
'''
def forward(self, x, targets=None, img_dim=None):
self.img_dim = img_dim
num_samples = x.size(0) #batchsize
grid_size = x.size(2) #
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size) #形状变化。
.permute(0, 1, 3, 4, 2)
.contiguous()
)
#其实输出只是一种变化方式,对先验框的变化方式。
# Get outputs
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# If grid size does not match current we compute new offsets
if grid_size != self.grid_size:
self.compute_grid_offsets(grid_size, cuda=x.is_cuda)
# Add offset and scale with anchors
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + self.grid_x
pred_boxes[..., 1] = y.data + self.grid_y
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride,
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1,
)
if targets is None:
return output, 0
首先预测结果包含坐标和类别概率和一个置信度,从代码可以看到预测坐标都是在0,1之间的数值,
x.data + self.grid_x 同时要给这个数值加上一个网格坐标,其实很明确,最后的中心点坐
标表示的是每个网格中的坐标,然后扩大缩放倍数后变成实际图片坐标。每个网格都会有三种不同
的尺寸先验框,所以一共有固定数目的很多框,二标签框不多。通过一种扩大缩小的mask技术,将
标签与输出对应
损失计算
我们的损失计算的是每个标签框与预测框的损失。其中回归损失是坐标和宽高损失,坐标损失计算
输出坐标与实际物体的中心坐标在单个网格中的位置。笼统的说其实YOLO是扫描所有的网格,
我们的预测也是网格中的坐标同时我们需要将实际标签转化到网格坐标中。 回归的是每个候选框
在一个区域内的位置。
#这段代码主要是让预测结果与标签可计算损失
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres): #anchors=[]
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0)#2
nA = pred_boxes.size(1)#3
nC = pred_cls.size(-1) #80
nG = pred_boxes.size(2)#26
# Output tensors
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0) #所有的大小都是网格大小
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1)
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0) #通过obj_mask我们会确定哪些输出会作为最后会进入损失函数
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG #在网格大小的尺寸上缩放
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors])
best_ious, best_n = ious.max(0)
# Separate target values
b, target_labels = target[:, :2].long().t()
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t()
# Set masks
obj_mask[b, best_n, gj, gi] = 1
noobj_mask[b, best_n, gj, gi] = 0
# Set noobj mask to zero where iou exceeds ignore threshold
for i, anchor_ious in enumerate(ious.t()):
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor() ###这块,非常难搞,表示将实际标签输出转化网格坐标中。
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1
# Compute label correctness and iou at best anchor
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
tconf = obj_mask.float()
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
总的来说就是变化网格坐标,将输出和标签都规划到网格大小,同时,计算所有网格对应的框的坐标。
预测
在预测的时候,预测结果是所有的框,三个尺度下一共有1万多个框 通过非极大值抑制来减少这些框。
具体怎么做呢,首先收集所有输出输出就是三个yolo的输出将他们变成一列。然后针对每张图片做处理
先把坐标变成左上角和右下角坐标,然后更具执行度筛选出一些框,设定阈值。然后找到每个框的类别概率
用概率乘置信度得到一个结果,根据这个结果对框排序。取最可能的框。计算所有的框对这个框的IOU值。
用IOU值找过滤掉一些重合度不高的,然后剩下的使用置信度作为加权值,将框进行求均值。得到平均的框
不废话了看代码
prediction[..., :4] = xywh2xyxy(prediction[..., :4]) #将框左边转化为顶点坐标。
output = [None for _ in range(len(prediction))] #几张图片
for image_i, image_pred in enumerate(prediction): #遍历所有图片
# Filter out confidence scores below threshold
image_pred = image_pred[image_pred[:, 4] >= conf_thres] #所有在4位置大于conf_thres的数据#通过置信度去掉一些框
# If none are remaining => process next image
if not image_pred.size(0):
continue
# Object confidence times class confidence
score = image_pred[:, 4] * image_pred[:, 5:].max(1)[0] #max可以输出索引
# Sort by it
image_pred = image_pred[(-score).argsort()] #从小到大排序的索引 取负相当于从大到小
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True) #保持原来数据的维度
detections = torch.cat((image_pred[:, :5], class_confs.float(), class_preds.float()), 1)
# Perform non-maximum suppression
keep_boxes = []
while detections.size(0):
large_overlap = bbox_iou(detections[0, :4].unsqueeze(0), detections[:, :4]) > nms_thres 通过IOU去掉一些框
label_match = detections[0, -1] == detections[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match #只保留符合条件的框。 &取的很精髓,保证了一张图上可以又相同类别的物体
weights = detections[invalid, 4:5]
# Merge overlapping bboxes by order of confidence
detections[0, :4] = (weights * detections[invalid, :4]).sum(0) / weights.sum() #将符合条件的框以置信度维权值求一个平均框
keep_boxes += [detections[0]] #保留一个框结果
detections = detections[~invalid] #遍历其他框。次小概率。
if keep_boxes:
output[image_i] = torch.stack(keep_boxes)