VGG
VGG的特点就是全部3*3卷积核,深度包含卷积核全连接,使用3*3的卷积核代替大的卷积,
两个33可以代替一个55,具体结构是卷积,标准化,激活函数。卷积后接自适应avgpool
7*7核 全连接部分的输出经过激活relu后需要叫dropout输入大小不会被限制,应为包含
了自适应pool。图像缩放主要依靠卷积中的maxpool 步长是2
ResNet
桶装的先是256通道变成64在从64变为256
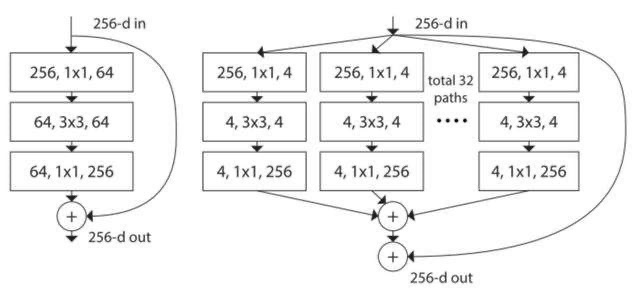
首先每个块都需要不改变输出的尺寸,左边是ResNet,三个一组,在梯度传递过程中会保证
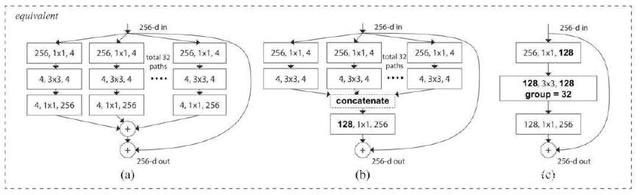
梯度会减少梯度消失或者爆炸的程度,右边的是ResNeXt的很简单了分n份每份做卷积然后求和, 这里的求和会造成类似一个拉普拉斯平滑的效果,方差会减小,不利于分类器的效果,
还有个其他结果可以RestNeXt就是级联,
DenseNet
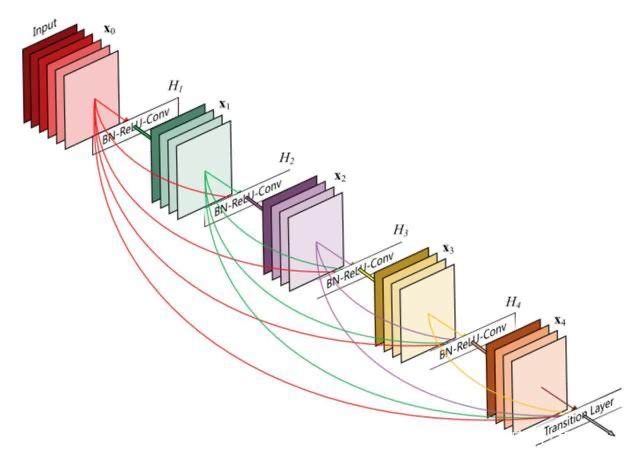
1、起始卷积:7*7卷积2步长、BN、ReLU、MaxPool步长2
2、每个输出都是固定大小的卷积,然后拼接前面的所有特征,输入到下一个卷积核
稠密网络所有的特征都会进行级联,级联的好处就是特征图的方差会增大,保证了特征的重用性
下面是一个稠密网络,可以看到会长生非常多的特征,前面的每一层残生的特征都会级联到后面
Inception
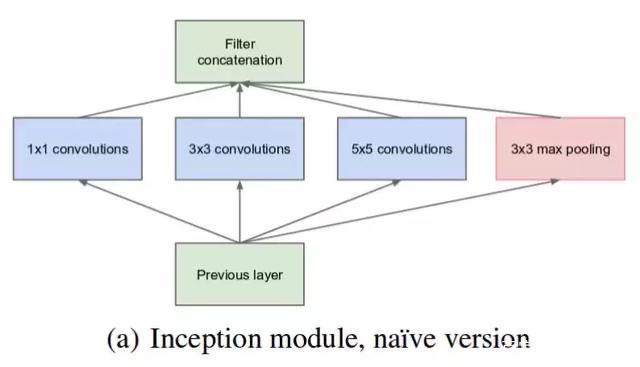
v1 是提出不同卷积核结果cat
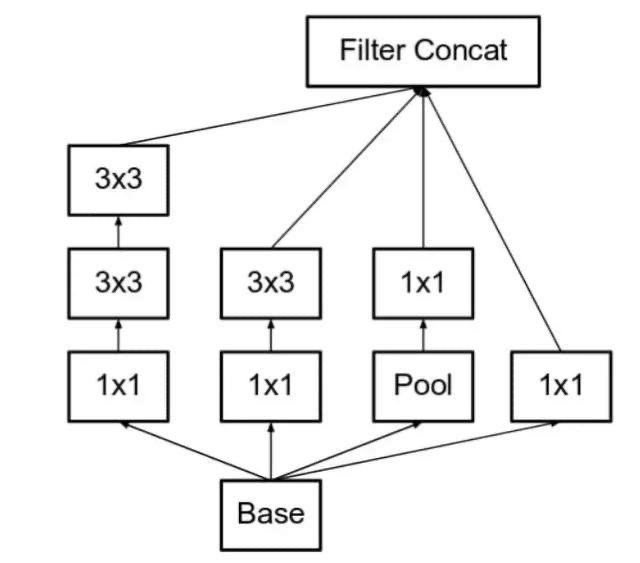
V2 使用连个3*3替换5*5
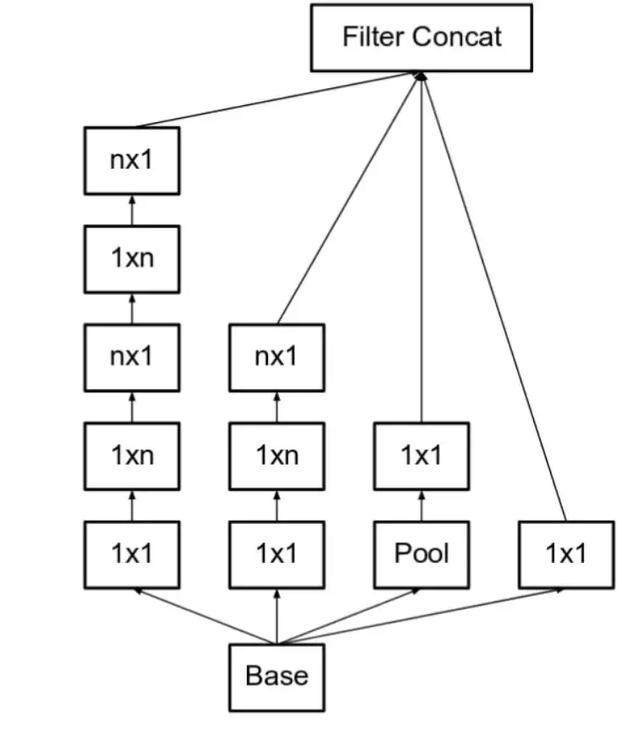
v3 使用1*n 和n*1 替换n*n
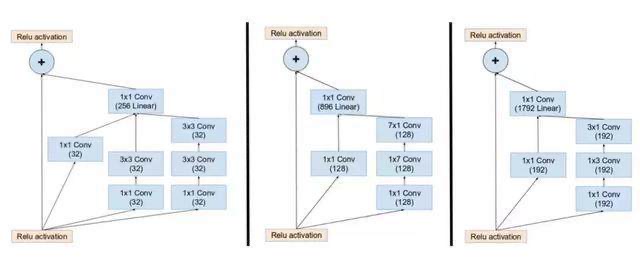
v4 将resnet模块部分替换成inception模块
谷歌提出的网络主要是inception模块很有思路,采用不同的卷积核分别进行卷积
然后得到结果在进行级联很不错的网络同时使用连续33的卷积核代替55的卷积核,
初代inception 不同的卷积核进行卷积然后级联。
改进,使用33代替55 然后增加一个1*1只是为了减少输出层数,然后减少参数个数
进一步的改进使用一维的卷积核多个可以实现更好的性能
也可以使用resnet核inception相结合的方式
mobilnet
深度可分离卷积 通过分组卷积实现 首先3*3卷积,然后1*1卷积
shufflenet
1、分组卷积导致特征之间没有信息交互
2、打乱特征图可以进行信息交互
3、打乱方式是矩阵变化再变化
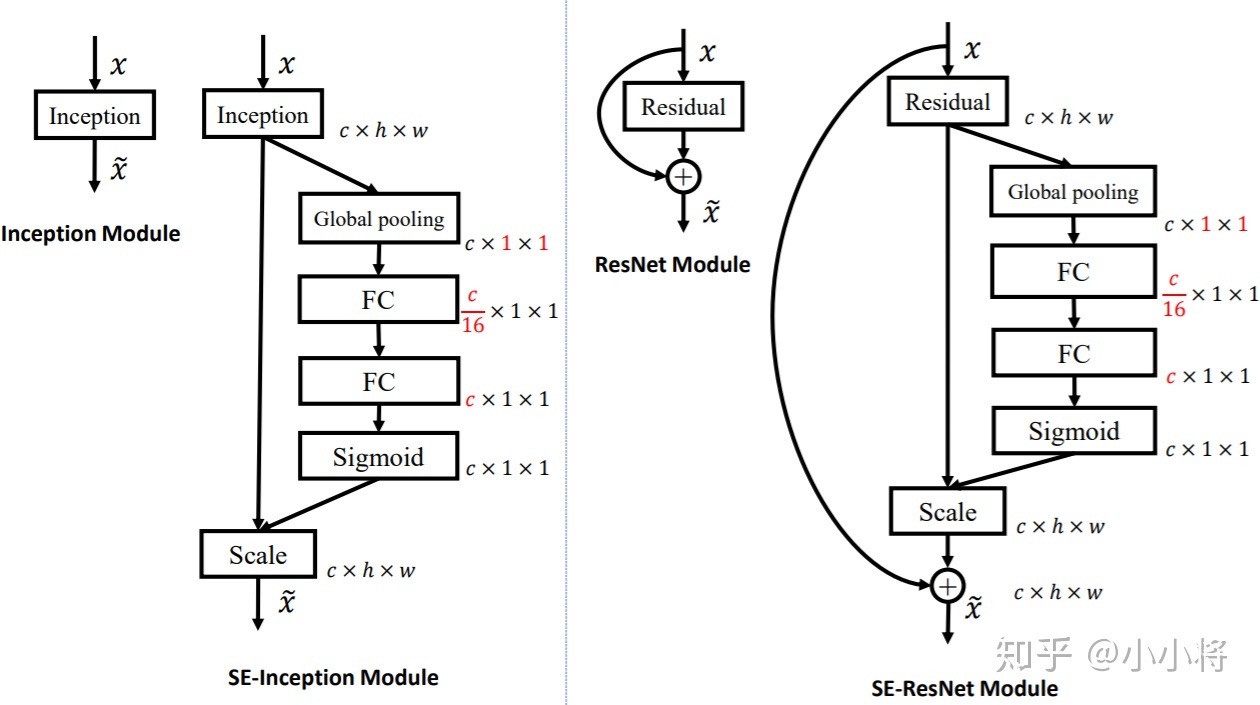
SEnet
这个就是一个描述通道间关系的网络,这个网络主要是通过一种手法描述了通道间某种关系,
增加了一些变量,对卷积的输出做自适应pooling输出通道数个表示没个通道的权值,
然后全连接,然后sigmoid