LSTM
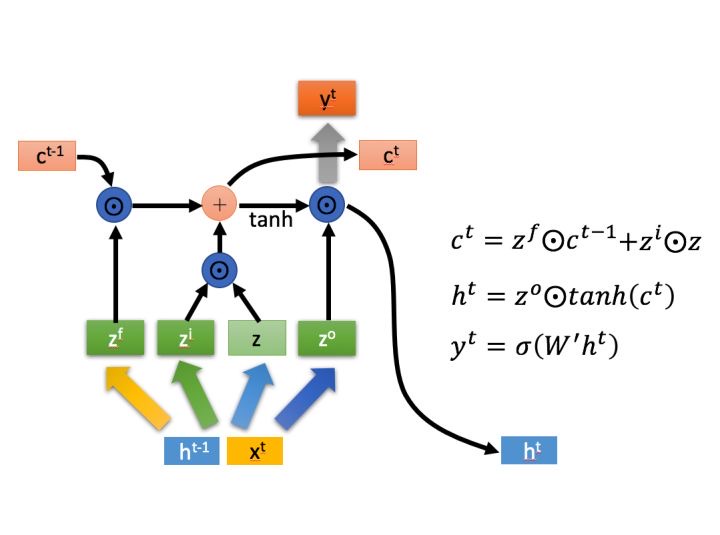
c表示这次又多少信息会保存到下一个单元,h表示当前的状态,y表示输出,其实h和y是一个意思
zf是控制上次的信息会有多少保留下来,zf=sigmoid(W*[h,x]) zf是01之间的值可以与c相乘表示
上次有多少信息保留下来,zi控制本次的输入有多少需要保留,上次保留的c加上本次的信息得到
下次c,其实c就是当前的输出了,但是为了保证当前输出是可变的所以乘zo控制有多少信息会作为
输出
$i_t = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{t-1} + b_{hi})$
$f_t = \sigma(W_{if} x_t + b_{if} + W_{hf} h_{t-1} + b_{hf})$
$g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hg} h_{t-1} + b_{hg})$
$o_t = \sigma(W_{io} x_t + b_{io} + W_{ho} h_{t-1} + b_{ho})$
$c_t = f_t \odot c_{t-1} + i_t \odot g_t$
$h_t = o_t \odot \tanh(c_t)$
权重共享体现在每个模块的权重都一样,参数量主要受输入输出维度和网络层数影响
CTC
ctc损失 在使用pytorch的时候我们可以把标签量设为一串数字然后长度设为固定
1. T = 50 #输出序列的长度,也就是步长。
2. C = 20 #类别是词库大小包括空格
3. N = 16 #一共又多少个样本
4. S = 30 #目标序列的最大长度
5. S_min = 10 #目标序列的最小长度
6. #如何理解input呢,T表示了又多少个RNN的块,N表示一次多少样本,C表示一个RNN快输出是多大也就是词库多大
7. input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
8. #目标值就是字典的索引,N表示有多少样本,S表示一个目标值的最大长度,我们知道对于句子
9. #目标句子有的长 5个字有的长7个字,我们的限制条件是不能超过最大长度,同时我们需要将
10. #5个字或者7个子都padding成最大长度
11. target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
12. #输入的长度表述 有N个样本每个样本的长度是T
13. input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
14. #目标的长度表示,有N个样本,每个样本根据实际情况确定长度是多少,为了截断被padding的目标序列
15. target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
16. ctc=nn.CTCLoss()
17. ctc(input,target,input_lengths,target_lengths)
targets建议将其shape设为(sum(target_lengths)),然后再由target_lengths进行输入序列长度指定就好了
,这是因为如果设定为(N, S),则因为S的标签长度如果是可变的,那么我们组装出来的二维张量的第一维
度的长度仅为min(S) 将损失一部分标签值(多维数组每行的长度必须一致),这就导致模型无法预测较长长度的标签