模型
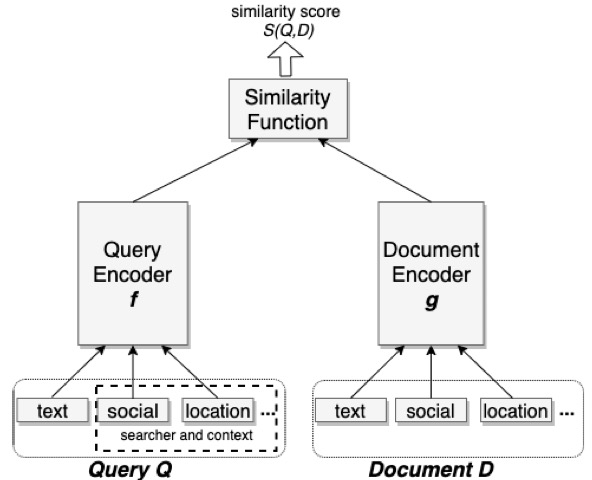
Embedding-based Retrieval in Facebook Search 两个模型输出两个结果
Triplet loss
一个模型输入query 另一个模型输入 正负样本doc
数据构建有门道
正负样本的构建
负样本有两种选择 1从召回结果中选择未点击的属于hard-case 2随机采样一个数据,
直观上hard-case作为结果似乎训练的模型更优秀,但是实际上hard-case为模型
添加了一种偏差,导致识别不准,反而随机采样的结果才准
正样本构建 使用点击的或者排序靠前数据的数据作为正样本,实验结果是一样的
FEATURED TAGS
c语言
c++
面向对象
指针
容器
python
函数
数据结构
回归
损失函数
神经网络
机器学习
似然函数
极大似然
标准化
深度学习
卷积网络
参数估计
beta分布
数据处理
gradio
模型工程化
网页
模型加速工具
c++实现
变量
占位符
tensorflow
线性回归
学习tensorflow
HMM
RNN
强化学习
LSTM
pandas
不定长序列损失
pytorch
目标检测
RPN
非极大值抑制
ROIpooling
VGG16
Transformer
BERT
Python
装饰器
方法
Pytorch
FPN
图像分类
CNN
多模态
生成
GPT
Tranformer
生成模型
audio