Transformer
出自google的经典论文 Attention is All YouNeed
除了未来5年内所有的技术都是在这个技术基础之上实现的
 结构之简单性能之强大可以说牛逼
结构之简单性能之强大可以说牛逼
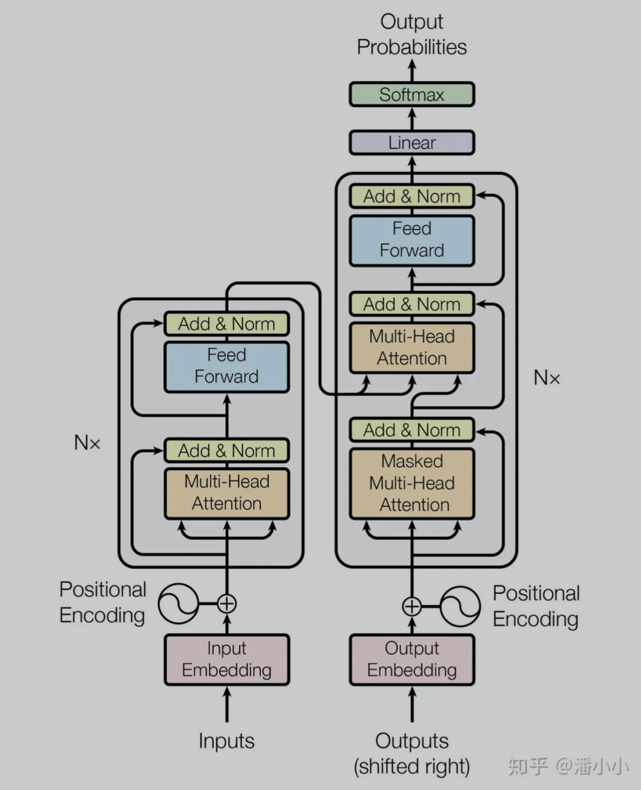
介绍一下这个结构
Encode
首先embedding不用多介绍主要是word embedding 和 位置embedding
计算求和后输出输出到attention QKV 交互 Q是索引,表示一句话的一个字
K 是一句话所有的字,用一个字计算所有的关系,然后将这个关系体现在V上
然后计算和输入的残差,再标准化,再经过FFD再计算残差和标准化
如此就是一个模块,多个模块串联就是encode结构
经典的BERT就是Encode结构,再损失上增加了MLM和句子判断模型
Decode
相比Encode更复杂一些 多了两个核心的一个是Mask的Attention一个是来自
Encode的输出也VK和Decode输出Q进行计算也就是cross Attention
Mask的Attention就是对qk矩阵进行mask 避免看到序列每个字后面的字的结果
GPT用的就是去掉cross Attention
细节
1、训练数据
输入一个文本A 和他的对应翻译句子B
B1 = B[:-1]
B2 = B[1:]
loss = ce(模型输出,B2)
2、测试数据
输入句子得到encode结果A
输入起始BOSembedding到decode
3、模型
encode是传统的bert输入 token和paddingmask得到句子编码
decode attention有两个 一个是先把句子进行selfatt(训练集就是B1,测试集就是起始位置BOSembedding)
mask使用featuremask上三角,然后使用encode全部输出去attention 其中encode的输出作为k,v decode输出最为q
mask使用encode的paddingmask
预测模型使用bos初始位置开始然后预测下一个然后把下一个加到序列继续预测