多模态大模型
延用了Beitv2的训练方式不通点在于
1、多模态
同时输入文本图像的图文对
建设一个专家系统,每个模态对应了一个专家系统
起始就是每个模态对应一下全连接,训练方式除了v2版本的还有一些模态匹配的
任务,综合起来就是mask data modeling 还原被mask的部分
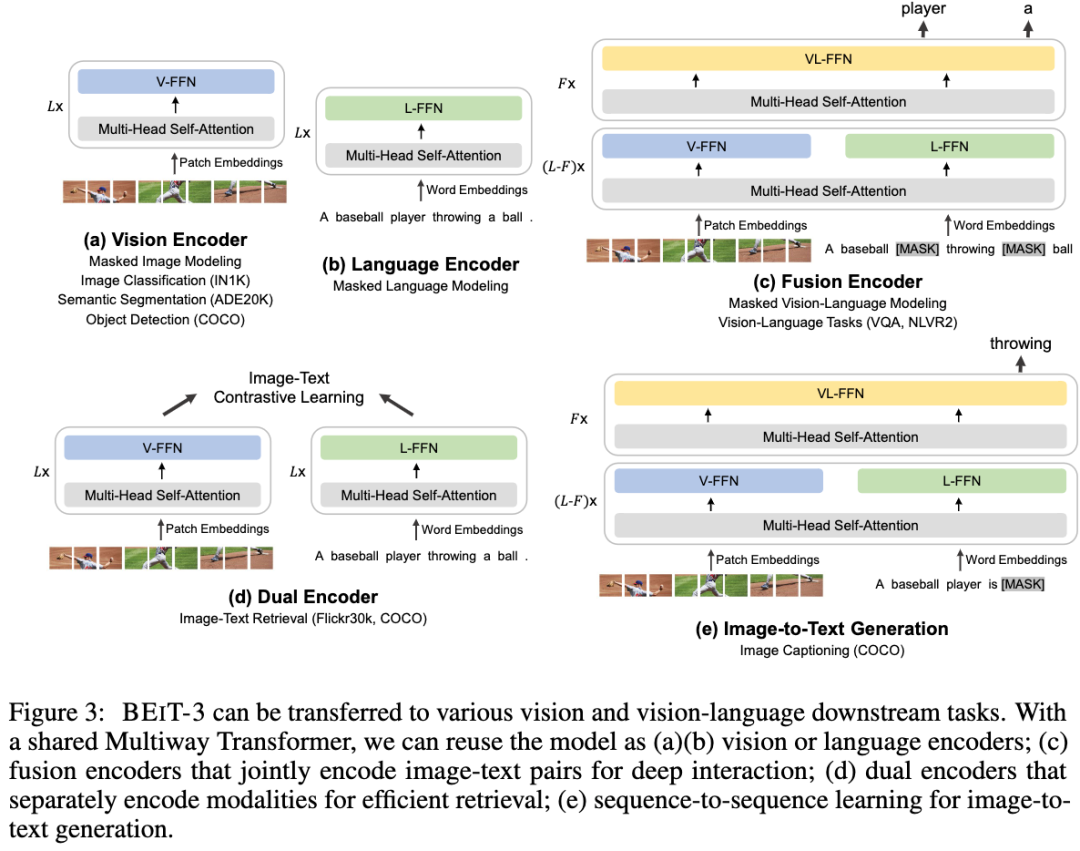
预训练
论文证明mask data modeling 才是预训练任务最正确的方式
对比学习预训练对batchsize比较敏感,batch越大效果越好,但是
batch大对资源是一种考验
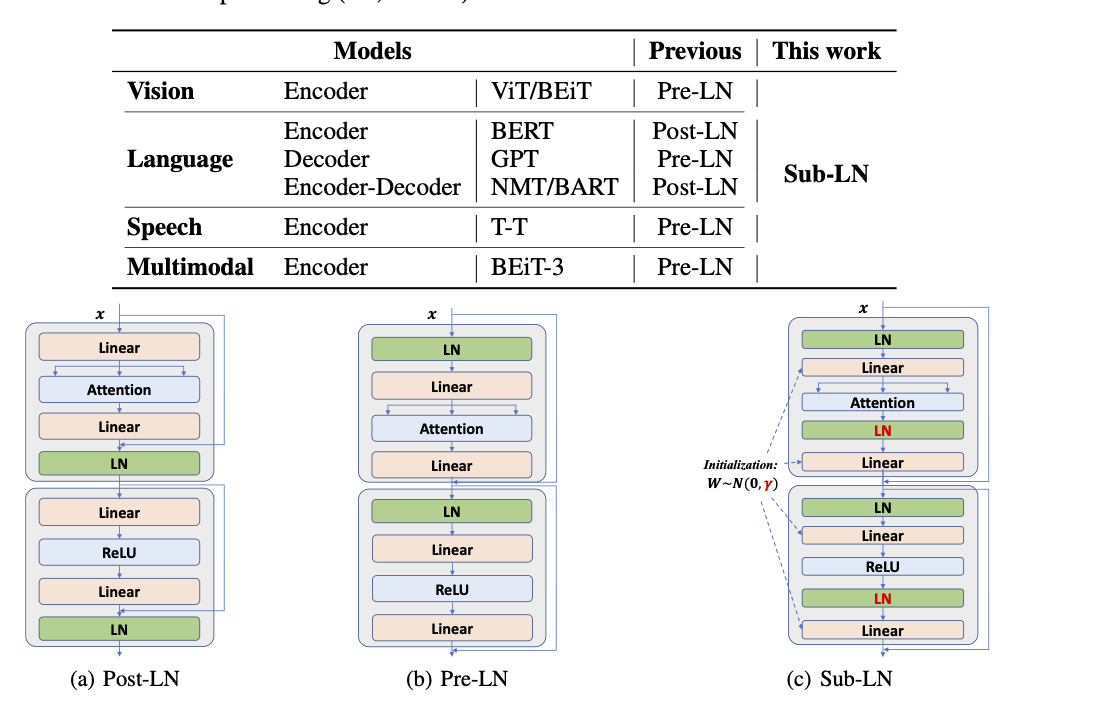
微软的骚操作
1、DeepNet
实现1000+层的Transformer训练,保持稳定
2、Foundation Transformers
对LN层进行调整
FEATURED TAGS
c语言
c++
面向对象
指针
容器
python
函数
数据结构
回归
损失函数
神经网络
机器学习
似然函数
极大似然
标准化
深度学习
卷积网络
参数估计
beta分布
数据处理
gradio
模型工程化
网页
模型加速工具
c++实现
变量
占位符
tensorflow
线性回归
学习tensorflow
HMM
RNN
强化学习
LSTM
pandas
不定长序列损失
pytorch
目标检测
RPN
非极大值抑制
ROIpooling
VGG16
Transformer
BERT
Python
装饰器
方法
Pytorch
FPN
图像分类
CNN
多模态
生成
GPT
Tranformer
生成模型
audio