说明
模型结构简单训练方式简单,数据简单,总之就是简单到不能再简单
数据处理
使用fastText过滤文档,fastText由CBOW而来
CBOW是连续词袋模型,简单理解就是一次词embedding,原理是用滑窗内一个词两边的词来表示中间词
模型结构就是一个dnn
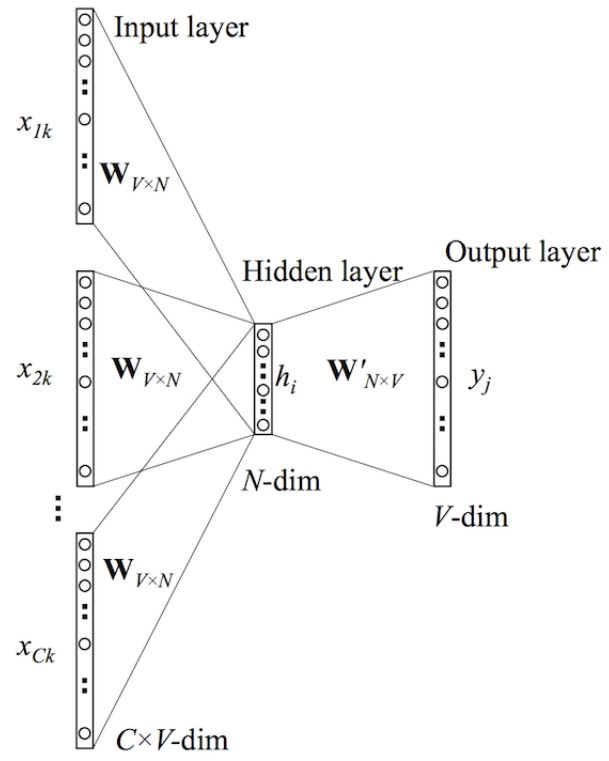
cbow的输入是目标词两边的词这里的C表示目标词两边C个词,每个词用onehot表示,每个与参数矩阵乘
之后求均值得到隐向量维度是1*N,N表示隐藏层维度,在通过一个N*V的参数矩阵还原得到1*V
使用softmax激活和目标结果的onehot向量做交叉熵计算得到损失。
每个词都可以使用onehot向量表示
模型结构和diff
Transformer结构,因果mask 和其他模型不同的地方有
标准化
区别于Layer Normalization没有减均值直接除方差
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
FeedForward
区别于常用的4d扩张 使用的是2/3*4*d维
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
提示学习和指示学习是至关重要的策略,提示学习是生成式的数据
实例:”中国的首都是**” 补全空白的位置,锻炼的模型的生成能力
指示学习是对模型发出指令,模型需要理解指令并做出解答,锻炼的
是模型的理解能力,实例:”翻译 我是中国人” 模型首先要理解我们
的目标是什么,然后给出正确的解答
这里GPT训练这两种数据都用到了。
训练数据主要包括
有监督数据
这里的数据是训练GPT3的数据也就是提示学习的数据
奖励模型学习
收集有监督的数据训练完后的GPT3 生成的结果GPT模型可以生成多个结果
主要原因在于生成结果取值时不是取的最优值而是在最优的几个里随机取一个
对于生成的一系列结果标准人员标注出这一些列结果的排名
继续训练,训来拿的目标是标注人员最喜欢的结果
模型结构
GPT3模型结构和GPT1 GPT2一样除了参数规模上有变化
层数96成 head 96 词典5w embedding 1.2w
按照这个参数保存了一下模型600G
模型都无法加载到GPU不过1.12版以后的pytorch可以使用
全新的训练算法实现训练