Pytorch
使用常规1.12以后的pytoch中的FSDP进行训练
https://arxiv.org/pdf/1811.06965.pdf
论文:GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
训练框架fairscale
https://cloud.tencent.com/developer/article/1882898
fairscale 使用
有张量并行和流水线并行,所谓张量并行是计算张量拆分到计算单元中
流水线并行是吧模型切片后通过微batch实现计算流程并行
使用流水线并行实现大模型训练
class A(torch.nn.Module):
def __init__(self):
super().__init__()
self.a = torch.nn.Linear(3,2)
self.b = torch.nn.Linear(2,3)
#print(self.a.weight.device)
def forward(self, data):
#print(x.shape)
#x.to(self.a.weight.device)
#print(x)
x, mask = data
print(x,mask)
x = self.a(x)
#print("x", x.shape)
x= self.b(x)
return (x, mask)
a= torch.rand(4,2).cuda(0)
a = torch.tensor([[1.,0,0],[1.,2,0]]).cuda(0)
mask = torch.tensor([1,2]).cuda(0)
model = torch.nn.Sequential(*[A() for i in range(4)])
#print(model)
model = fairscale.nn.Pipe(model, balance=[1, 1,1,1], devices=[0, 1,2,3], chunks=2)
c = model((a, mask))
print(c[0].shape)
print('done')
####模型并行
一般情况下如a图所示数据单向行走,走完GPU1走GPU2此时GPU1限制,浪费了资源
将数据划分成微batch,在原来batch基础上进一步划分(chunks参数决定划分几个微batch)
如图c所示,所有微batch前向传播走完后开始走后向,后向过程和前向过程一样逐步更新。
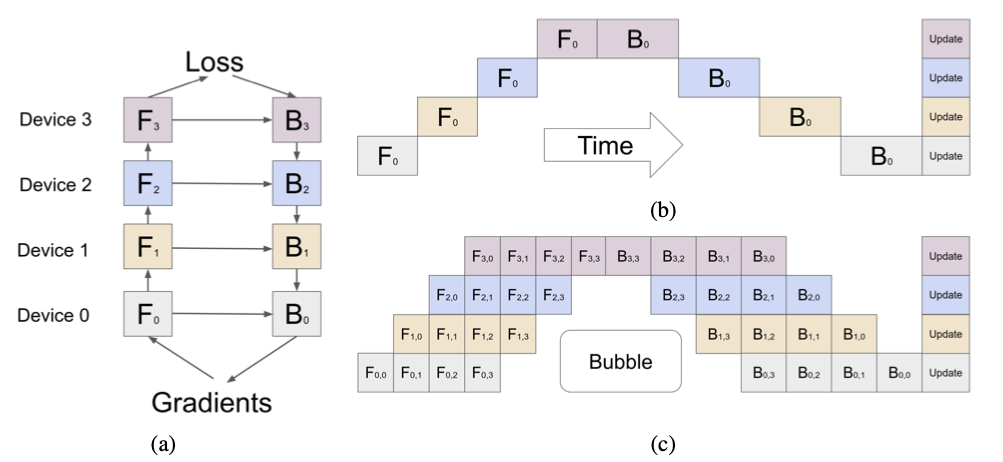 前向过程cuda0走第一个微batch cuda0计算完后计算第二个微batch同时cuda1计算第一个微batch
前向过程cuda0走第一个微batch cuda0计算完后计算第二个微batch同时cuda1计算第一个微batch
反向过程一样,(横向代表时间)
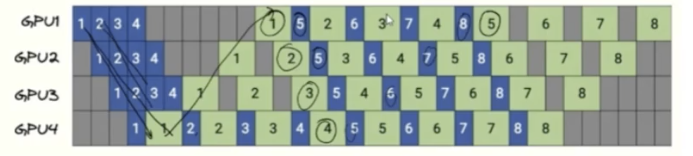
####模型进一步并行
第一个微batch走完后直接更新梯度走反向,蓝色表示正向传播,绿色表示反向传播可以更大限度的
利用GPU。这里有个问题可以看到当第5个微batch过来的时候通过GPU1上的模型是更新过一次参数的
模型,通过GPU2上的模型是更新过两次参数的模型
大模型finetuning
常见的大模型finetuing方法
迁移学习
冻结部分层特征然后训练前几层,或者使用大模型跑出特征保存然后建一个小模型用这些
特征训练小模型
adapter-tuning
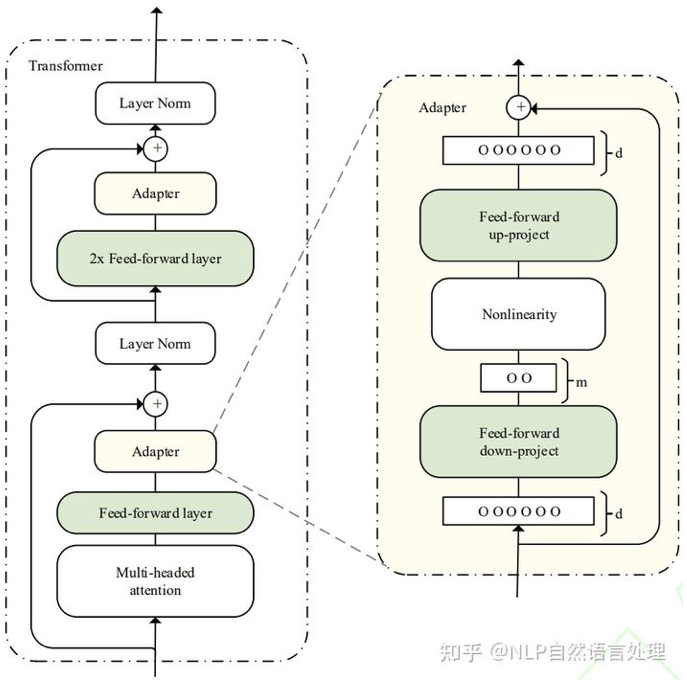 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,
在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,
由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,
第一个前馈子层将Transformer块的输出作为输入,将原始输入维度d投影到m,
通过控制m的大小来限制Adapter模块的参数量
Prompt-tuning
就是给输出加入提示训练
Prompt的本质是一种对预训练任务的复用,实现基于Prompt的统一范式
当数据集不同(乃至样本不同)的时候,我们期望模型能够自适应的选择不同的模板,
这也相当于说不同的任务会有其对应的提示信息。例如在对电影评论进行二分类的时候,
最简单的提示模板是“[x]. It was [mask].”,但是其并没有突出该任务的具体特性,
我们可以为其设计一个能够突出该任务特性的模板,例如“The movie review is [x].
It was [mask].”,然后根据mask位置的输出结果通过Verbalizer映射到具体的标签上。
这一类具备任务特性的模板可以称之为指令(Instruction)。
指示学习的模板可以设计成自回归形式的把结果放在最后token上,万物皆可生成。可以设计成抽取式的类似NER
答案放在文本中万物皆可抽取。还有第三种是类似bert中NSP判断是否为下一句,将问题和答案看成两句话
判断是否来自同一句
大模型构建提示主要有三种方法
上下文学习 In-Context Learning(ICL):直接挑选少量的训练样本作为该任务的提示
类似one-short 或者few-short
指令学习 Instruction-tuning:构建任务指令集,促使模型根据任务指令做出反馈
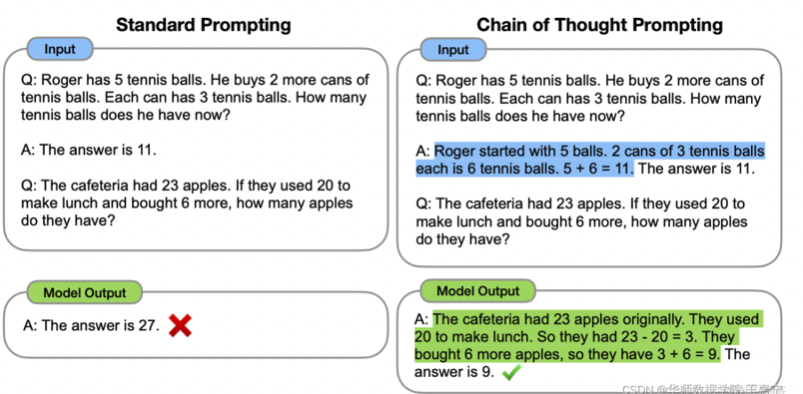
思维链 Chain-of-Thought(CoT):给予或激发模型具有推理和解释的信息,通过线性链式的模式指导模型生成合理的结果。
LORA
adapter额外增加了模型层数会增加模型推理时间,Prompt序列会变长压缩输入序列空间
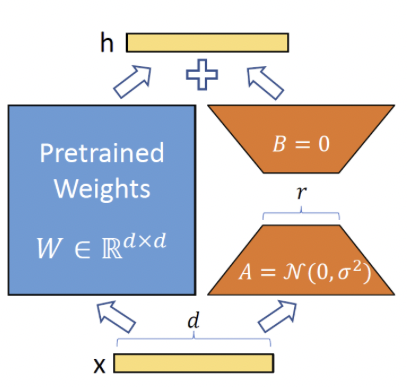
在原始PLM旁边增加一个旁路,做一个降维再升维的操作。训练的时候固定PLM的参数,
只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。
用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
https://blog.51cto.com/u_15775105/6221301
https://zhuanlan.zhihu.com/p/624918286
函数解析
DistributedSampler
对epoch内数据进行拆分,每个epoch内数据按照卡数拆分,有随机和顺序两种方式
DistributedSampler返回的是数据位置索引,这里的rand表示当前进程中的第几张卡
total_size表示一个epoch内有多少条数据 num_replicas=total_size/一共的卡数
最终返回的是一个数据位置索引迭代器。
def __iter__(self) -> Iterator[int]:
if self.shuffle:
# deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = torch.randperm(len(self.dataset), generator=g).tolist() # type: ignore[arg-type]
else:
indices = list(range(len(self.dataset))) # type: ignore[arg-type]
if not self.drop_last:
# add extra samples to make it evenly divisible
padding_size = self.total_size - len(indices)
if padding_size <= len(indices):
indices += indices[:padding_size]
else:
indices += (indices * math.ceil(padding_size / len(indices)))[:padding_size]
else:
# remove tail of data to make it evenly divisible.
indices = indices[:self.total_size]
assert len(indices) == self.total_size
# subsample
indices = indices[self.rank:self.total_size:self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)
spawn
spawn函数包括了模型训练的整个周期,包括数据读取,模型训练更新和保存参数
mp.spawn(fn, nprocs,args)
该函数的作用是生成使用 args参数运行fn的nprocs个进程。
fn:第一个参数是一个函数,每个进程要运行的函数。
nprocs: 第二个参数是开启的进程数目。
args:第三个参数是fn的函数实参,需要注意的是fn函数的第一个参数是进程的id,不用写入args中,spawn会自动分配。
如果我们有三张卡,那会启动三个进程 每个进程内都是单独读取数据,数据读取采样器使用DistributedSampler
而该函数的输入包括rank也就是gpu号,和随机种子,而随机种子由epoch控制,所以根据读取方式每张卡都可以读到epoch内
不重复的数据