模型结构
模型有Eencode和Decode结构还有两种一起用的,到底哪种模型结构最好用呢
论文:Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
论文:BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
论文:GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
从秩的角度看待attention的效果和性能,为啥需要全连接为啥需要残差链接
矩阵的秩代表了矩阵包含的信息多少,对矩阵进行初等变化,变为三角矩阵,非0行的数量就是矩阵的秩
这项工作提出了一种理解自注意网络(SANs)的新方法。这项工作提供了关于由多个自我注意层
堆叠而成的网络的操作和感应偏向的新见解。它们的输出可以分解为一个较小项的总和,每个项都
涉及一个跨层注意头序列的操作。通过这种分解,证明了自我注意对”令牌均匀性“具有强烈的诱导偏向。
具体地说,在没有跳连接或多层感知器的情况下,输出按指数倍数收敛到一个秩-1矩阵。另一方面,
跳连接和MLP会阻止输出退化。即仅仅由(Self-)Attention构成的网络(去掉FFN、残差连接、LN)中,
随着输入在网络中向前传播,注意力分布的rank会逐渐降低,最后退化成一个uniform的分布。
而Transformer中的其他构件(FFN、残差连接)可以缓解这个问题。
大模型位置编码
位置编码主要研究思路是考虑长度外推,考虑超长文本或者多轮对话,绝对位置变化无法实现,普通
相对位置编码也很难实现
ALiBi位置嵌入
旋转位置编码
常见训练策略

1、Full language modeling (FLM):CD类的模型架构常用FLM。CD=Causal-Decode
通过上文预测当前 token。在训练时,每个 token 可以并行计算出 loss,预测时要迭代预测。
2、Prefix language modeling (PLM):ND 类和 ED 类的模型架构可以用 PLM。
首先在 attention 矩阵中定义一段 prefix,训练时要求模型生成 prefix 后面的 tokens。
3、Masked language modeling (MLM):只用 Encoder 的模型常用 MLM 目标。
后来在 T5 这个 seq2seq 模型里,也使用了整段 mask 的 MLM 任务。
结论
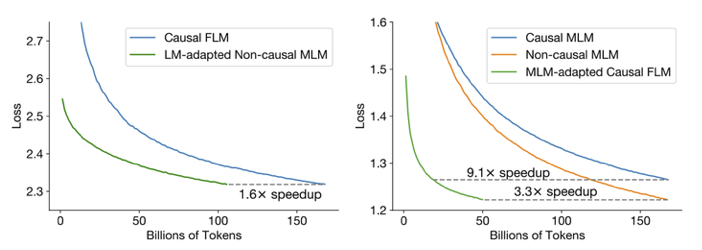 如果想最低成本的构建效果好的大模型,那就用 CD + FLM 预训练,
如果想最低成本的构建效果好的大模型,那就用 CD + FLM 预训练,
然后再改用 ND + MLM 做适应任务,最后再使用多任务微调。
这样的训练方式要比直接训练提速 9.1 倍,同时效果最好。