模型结构
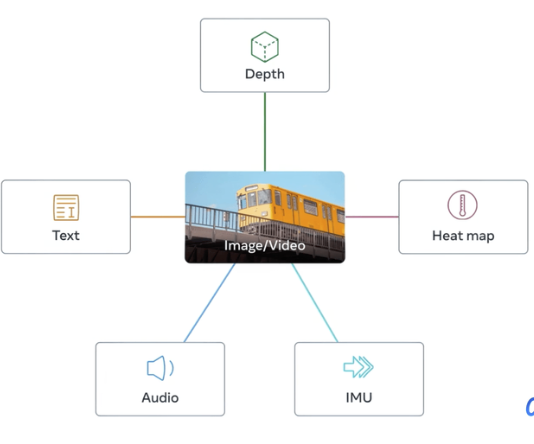
1、6个Transformer 分别对应六种模态,
2、每个模态有个head
3、对每种模态输出加一个参数,这个参数控制占比
4、核心思想是对齐模态都和图像模态对齐,图片和文本模态使用CLIP对模型进行初始化
其他模态和图像进行对齐训练,所用模态都和图像模态对齐,这样就对齐了所有模态
video模态
使用clip初始化,vit模型,不同的是输入的是video 使用3d卷积切片
使用绝对位置编码,其他tirck没有,3d卷积后展开方式和2d一样拉平
视频和图像的处理完全一致,时间维度(帧)直接拉平,位置编码的长度THW
B C (T) H W -> B T*H*W C
使用3d卷积展开
class PatchEmbedGeneric(nn.Module):
def __init__(self, proj_stem, norm_layer: Optional[nn.Module] = None):
super().__init__()
if len(proj_stem) > 1:
self.proj = nn.Sequential(*proj_stem)
else:
# Special case to be able to load pre-trained models that were
# trained with a standard stem
self.proj = proj_stem[0]
self.norm_layer = norm_layer
def get_patch_layout(self, img_size):
with torch.no_grad():
dummy_img = torch.zeros(
[
1,
]
+ img_size
)
dummy_out = self.proj(dummy_img)
embed_dim = dummy_out.shape[1]
patches_layout = tuple(dummy_out.shape[2:])
num_patches = np.prod(patches_layout)
return patches_layout, num_patches, embed_dim
def forward(self, x):
x = self.proj(x)
# B C (T) H W -> B (T)HW C
x = x.flatten(2).transpose(1, 2)
if self.norm_layer is not None:
x = self.norm_layer(x)
return x
audio模态
对音频分段然后提取Fbank特征,论文中使用的每段2秒中 一共3段(有交叉)
输出音频128*204,其中128是mel滤波器数量,204是输出帧数,最终的输出
3*1*128*204其中3表示3段音频。每段音频可以单独看成一条数据,
在最后处理中用均值合并, 使用2d卷积对频谱图切片,音频切断并不是无交叉
卷积核是16步长是10,同样卷积后在第二个维度拉平和图片操作一样
audio_stem = PatchEmbedGeneric(
proj_stem=[
nn.Conv2d(
in_channels=1,
kernel_size=audio_kernel_size, #16
stride=audio_stride, #10
out_channels=audio_embed_dim, #768
bias=False,
),
],
norm_layer=nn.LayerNorm(normalized_shape=audio_embed_dim),
)
text模态
文本模态就是自回归模型 CLIP文本端
depth模态
和图像一样
红外模态
和图像一样
坐标模态
FEATURED TAGS
c语言
c++
面向对象
指针
容器
python
函数
数据结构
回归
损失函数
神经网络
机器学习
似然函数
极大似然
标准化
深度学习
卷积网络
参数估计
beta分布
数据处理
gradio
模型工程化
网页
模型加速工具
c++实现
变量
占位符
tensorflow
线性回归
学习tensorflow
HMM
RNN
强化学习
LSTM
pandas
不定长序列损失
pytorch
目标检测
RPN
非极大值抑制
ROIpooling
VGG16
Transformer
BERT
Python
装饰器
方法
Pytorch
FPN
图像分类
CNN
多模态
生成
GPT
Tranformer
生成模型
audio