论文摘要
没啥新东西,就是VIT加上扩散模型理论那套东西,模型代码很整洁,带有通用性质。
VIT更注重图像的整体结构,对具体细节不关心用毫无创新来形容不为过吧
创新点
几个技术整合在一起
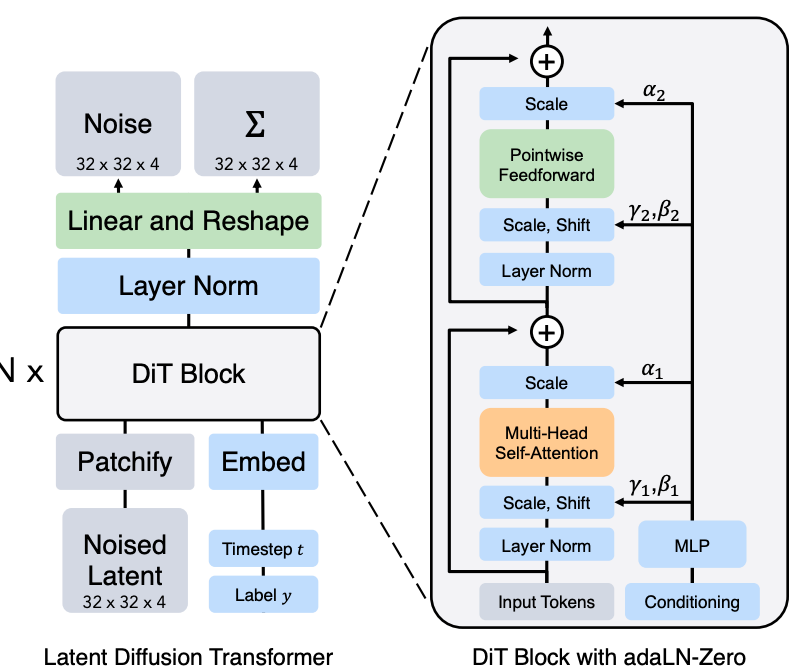
1、输入
数据输入vae编码的特征 类似LDM的输入,然后通过patch操作将拉平
2、CFG
条件输入和LDM一样先对类别做embedding然后加上时间步长特征输入
3、条件注入
在DIT模块中去掉标准化中的可学习变量这些变量原本是为了弥补标准化时带来的分布偏差。
使用CFG条件信息通过一个MLP获得偏移量,这些即可以用来弥补分布偏差也是条件信息
4、输出
模型输出均值和方差,采样函数通过均值和方差计算每一步实际图像
技术细节
import torch
import torch.nn as nn
import numpy as np
import math
from timm.models.vision_transformer import PatchEmbed, Attention, Mlp
def modulate(x, shift, scale): ##计算标准化后的补偿先缩放在平移也是信息注入的步骤
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
class TimestepEmbedder(nn.Module):
"""
每张图片都随机一个步长时间,使用正余弦方式创建向量再经过mlp获得时间条件
Embeds scalar timesteps into vector representations.
"""
def __init__(self, hidden_size, frequency_embedding_size=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(frequency_embedding_size, hidden_size, bias=True),
nn.SiLU(),
nn.Linear(hidden_size, hidden_size, bias=True),
)
self.frequency_embedding_size = frequency_embedding_size
@staticmethod
def timestep_embedding(t, dim, max_period=10000):
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=t.device)
args = t[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
def forward(self, t):
t_freq = self.timestep_embedding(t, self.frequency_embedding_size)
t_emb = self.mlp(t_freq)
return t_emb
class LabelEmbedder(nn.Module):
"""
对输入的类别进行embedding生成输入条件,有一定概率不包含条件
Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance.
"""
def __init__(self, num_classes, hidden_size, dropout_prob):
super().__init__()
use_cfg_embedding = dropout_prob > 0
self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
self.num_classes = num_classes
self.dropout_prob = dropout_prob
def token_drop(self, labels, force_drop_ids=None):
"""
Drops labels to enable classifier-free guidance.
"""
if force_drop_ids is None:
drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob
else:
drop_ids = force_drop_ids == 1
labels = torch.where(drop_ids, self.num_classes, labels)
return labels
def forward(self, labels, train, force_drop_ids=None):
use_dropout = self.dropout_prob > 0
if (train and use_dropout) or (force_drop_ids is not None):
labels = self.token_drop(labels, force_drop_ids)
embeddings = self.embedding_table(labels)
return embeddings
class DiTBlock(nn.Module):
"""
使用VIT代替Unet模型的核心,输入的类别时间条件再此处嵌入到模型,同时保证分布稳定性
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x
class FinalLayer(nn.Module):
"""
模型输出预测噪声的期望和方差所以输出是两部分
The final layer of DiT.
"""
def __init__(self, hidden_size, patch_size, out_channels):
super().__init__()
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 2 * hidden_size, bias=True)
)
def forward(self, x, c):
shift, scale = self.adaLN_modulation(c).chunk(2, dim=1)
x = modulate(self.norm_final(x), shift, scale)
x = self.linear(x)
return x
class DiT(nn.Module):
"""
Diffusion model with a Transformer backbone.
"""
def __init__(
self,
input_size=32,
patch_size=2,
in_channels=4,
hidden_size=1152,
depth=28,
num_heads=16,
mlp_ratio=4.0,
class_dropout_prob=0.1,
num_classes=1000,
learn_sigma=True,
):
super().__init__()
self.learn_sigma = learn_sigma
self.in_channels = in_channels
self.out_channels = in_channels * 2 if learn_sigma else in_channels
self.patch_size = patch_size
self.num_heads = num_heads
self.x_embedder = PatchEmbed(input_size, patch_size, in_channels, hidden_size, bias=True) #对输入隐变量取patch操作并拉长
self.t_embedder = TimestepEmbedder(hidden_size)
self.y_embedder = LabelEmbedder(num_classes, hidden_size, class_dropout_prob)
num_patches = self.x_embedder.num_patches
# Will use fixed sin-cos embedding:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, hidden_size), requires_grad=False)
#拉长后需要位置编码
self.blocks = nn.ModuleList([
DiTBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(depth)
])
self.final_layer = FinalLayer(hidden_size, patch_size, self.out_channels)
self.initialize_weights()
def initialize_weights(self):
# 初始化有技巧
# 在关于残差网络的研究中,发现将每个残差块初始化为恒等函数更容易训练。例如,在每个res block中将最后
# 一个batch norm的缩放因子初始化为零,可以加速有监督模型的训练。扩散U-Net模型也使用了类似的初始化策略,
# 在任何残差连接之前将每个block的最后一个卷积层初始化为零。
# Initialize transformer layers:
def _basic_init(module):
if isinstance(module, nn.Linear):
torch.nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
self.apply(_basic_init)
# Initialize (and freeze) pos_embed by sin-cos embedding:
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.x_embedder.num_patches ** 0.5))
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
w = self.x_embedder.proj.weight.data
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
nn.init.constant_(self.x_embedder.proj.bias, 0)
# Initialize label embedding table:
nn.init.normal_(self.y_embedder.embedding_table.weight, std=0.02)
# Initialize timestep embedding MLP:
nn.init.normal_(self.t_embedder.mlp[0].weight, std=0.02)
nn.init.normal_(self.t_embedder.mlp[2].weight, std=0.02)
# Zero-out adaLN modulation layers in DiT blocks:
for block in self.blocks:
nn.init.constant_(block.adaLN_modulation[-1].weight, 0)
nn.init.constant_(block.adaLN_modulation[-1].bias, 0)
# Zero-out output layers:
nn.init.constant_(self.final_layer.adaLN_modulation[-1].weight, 0)
nn.init.constant_(self.final_layer.adaLN_modulation[-1].bias, 0)
nn.init.constant_(self.final_layer.linear.weight, 0)
nn.init.constant_(self.final_layer.linear.bias, 0)
def unpatchify(self, x):
"""
x: (N, T, patch_size**2 * C)
imgs: (N, H, W, C)
"""
c = self.out_channels
p = self.x_embedder.patch_size[0]
h = w = int(x.shape[1] ** 0.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], c, h * p, h * p))
return imgs
def forward(self, x, t, y):
"""
Forward pass of DiT.
x: (N, C, H, W) tensor of spatial inputs (images or latent representations of images)
t: (N,) tensor of diffusion timesteps
y: (N,) tensor of class labels
"""
x = self.x_embedder(x) + self.pos_embed # (N, T, D), where T = H * W / patch_size ** 2
t = self.t_embedder(t) # (N, D)
y = self.y_embedder(y, self.training) # (N, D)
c = t + y # (N, D)
for block in self.blocks:
x = block(x, c) # (N, T, D)
x = self.final_layer(x, c) # (N, T, patch_size ** 2 * out_channels)
x = self.unpatchify(x) # (N, out_channels, H, W)
return x
def forward_with_cfg(self, x, t, y, cfg_scale):
"""
Forward pass of DiT, but also batches the unconditional forward pass for classifier-free guidance.
"""
# https://github.com/openai/glide-text2im/blob/main/notebooks/text2im.ipynb
half = x[: len(x) // 2]
combined = torch.cat([half, half], dim=0)
model_out = self.forward(combined, t, y)
# For exact reproducibility reasons, we apply classifier-free guidance on only
# three channels by default. The standard approach to cfg applies it to all channels.
# This can be done by uncommenting the following line and commenting-out the line following that.
# eps, rest = model_out[:, :self.in_channels], model_out[:, self.in_channels:]
eps, rest = model_out[:, :3], model_out[:, 3:]
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)
eps = torch.cat([half_eps, half_eps], dim=0)
return torch.cat([eps, rest], dim=1)